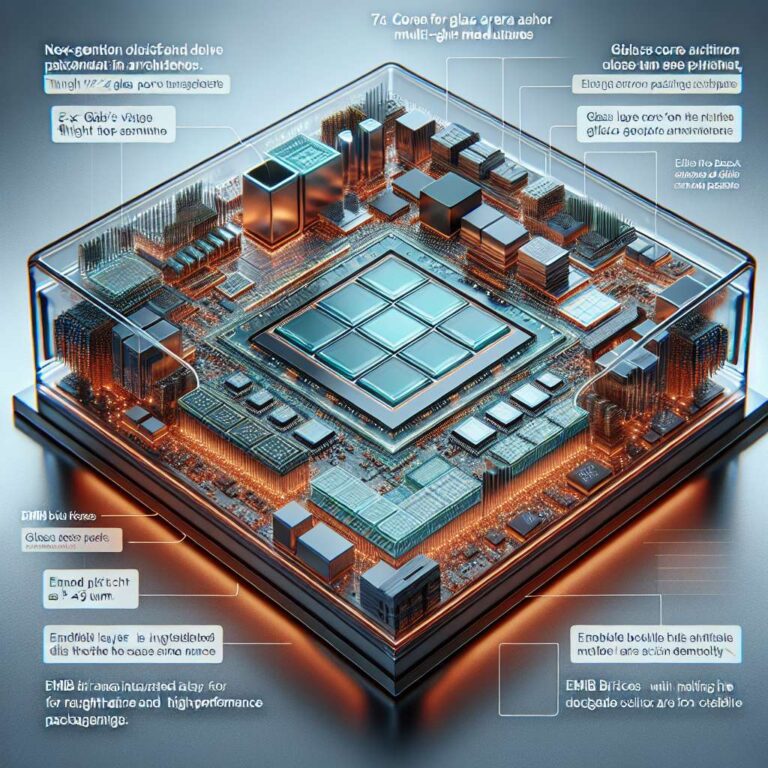
At NEPCON Japan 2026, Intel showcased a new glass substrate technology aimed at powering the next generation of advanced Artificial Intelligence and high performance computing accelerators. According to SemiVision Taiwan, Intel has created a high performance core glass substrate measuring 78×77 mm for the entire package. This substrate can accommodate approximately twice the reticle size with silicon, equating to about 1,716 mm² (2×858 mm²) of silicon area for logic and memory.
Intel describes this as the first 10-2-10-thick glass core substrate that integrates its EMIB multi chip module technology. The 10-2-10 designation refers to 10 redistribution layer build up layers on the top of the substrate, a 2 layer glass core, and 10 build up layers on the bottom side. The 10 redistribution layer (RDL) build up layers on the top of the substrate are used to redistribute signals from the die, and these layers handle fine pitch routing, with Intel dedicating as many as 10 layers for this purpose.
The core of the glass substrate consists of two layers and is made of 800 μm (or 0.8 mm) class material, which may include embedded metal layers for through-glass-vias or power and ground planes. The final ’10’ number denotes the number of build up layers on the bottom side, mirroring the top for symmetric routing to connect to the motherboard or PCB, and this bottom stack helps declutter the dense wiring from the silicon die so it can interface more cleanly with a standard board. Intel’s 10-2-10 glass core substrate is also equipped with some of the finest bump pitches in the market, with 45 μm (only 0.045 mm) bump pitch. Finally, Intel embeds two EMIB bridges for multi-chip-module packaging so you can manufacture several smaller dies and interconnect them via EMIB bridge, present on the glass core.