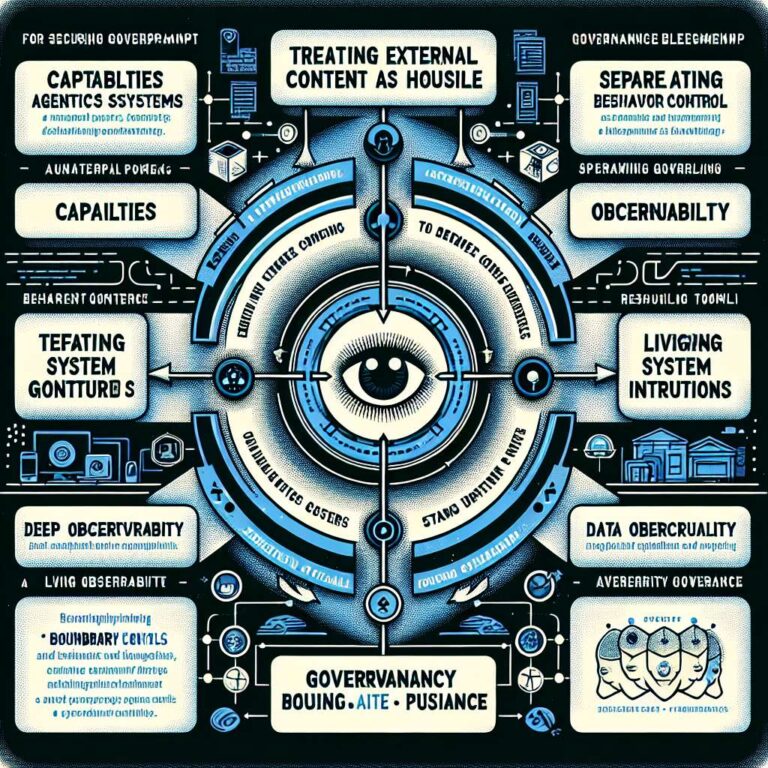
Enterprises adopting agentic systems are being advised to treat these systems as powerful, semi-autonomous users and to govern them at the boundaries where they interact with identity, tools, data, and outputs. Rather than relying on prompt-level constraints, security guidance from standards bodies, regulators, and major providers converges on boundary controls that can be governed and audited. A proposed eight-step plan groups controls into three pillars that constrain capabilities, control data and behavior, and prove governance and resilience, giving boards and CEOs concrete questions they can ask and expect to see answered with evidence instead of assurances.
The first pillar focuses on constraining capabilities by redefining how agents are identified and what they can do. Agents should be treated as non-human principals with narrowly scoped roles, running as the requesting user in the correct tenant, with permissions aligned to role and geography and with high-impact actions requiring explicit human approval and recorded rationale. Tooling must be controlled like a supply chain, with pinned versions of remote tool servers, formal approvals for adding tools, scopes, or data sources, and explicit policies for any automatic tool-chaining, aligning with OWASP concerns about excessive agency and with the EU AI Act Article 15 obligations on robustness and cybersecurity. Permissions should be bound to tools and tasks rather than to models, with credentials and scopes rotated and auditable, so that an agent such as a finance operations assistant can be allowed to read but not write ledgers without specific approval, and so that individual capabilities can be revoked without a full system redesign.
The second pillar targets data and behavior by treating external content as hostile until vetted, separating system instructions from user content, and gating all new retrieval sources before they enter memory or retrieval-augmented generation workflows, including tagging sources, disabling persistent memory in untrusted contexts, and tracking provenance. Outputs that can trigger side effects must never execute solely because a model produced them, and instead require validators that inspect agent outputs before code, credentials, or other artifacts reach production environments or users, following OWASP insecure output handling guidance and browser origin-boundary practices. Runtime data privacy is positioned as protecting data first and models second, using tokenization or masking by default with policy-controlled detokenization at output boundaries and comprehensive logging, which limits blast radius if an agent is compromised and provides evidence of risk control under regimes such as the EU AI Act, GDPR, and sector regulations.
The third pillar addresses governance and resilience by insisting on continuous evaluation and robust inventory and audit practices. Agents should be instrumented with deep observability and subjected to regular red teaming and adversarial test suites, with failures captured as regression tests and drivers for policy updates, reflecting concerns about sleeper agents described in recent research. Organizations are urged to maintain a living catalog and unified logs covering which agents exist on which platforms, what scopes, tools, and data each can access, and the details of every approval, detokenization, and high-impact action, enabling reconstruction of specific decision chains. A system-level threat model is recommended that assumes a sophisticated adversary is already present, aligns with frameworks like MITRE ATLAS, and recognizes that attackers target systems rather than individual models. Collectively, these controls reposition Artificial Intelligence access and actions within familiar enterprise security frames used for powerful users and systems, and shift board-level focus from generic guardrails to verifiable answers to specific governance questions.